StandbyMP will revolutionize how organizations manage DR enterprise-wide by making the same Gold Standard of DR available to both Oracle SE and MS SQL Server users - all from a single common user interface.
Disaster Recovery for Oracle SE, SQL Server and Postgresql
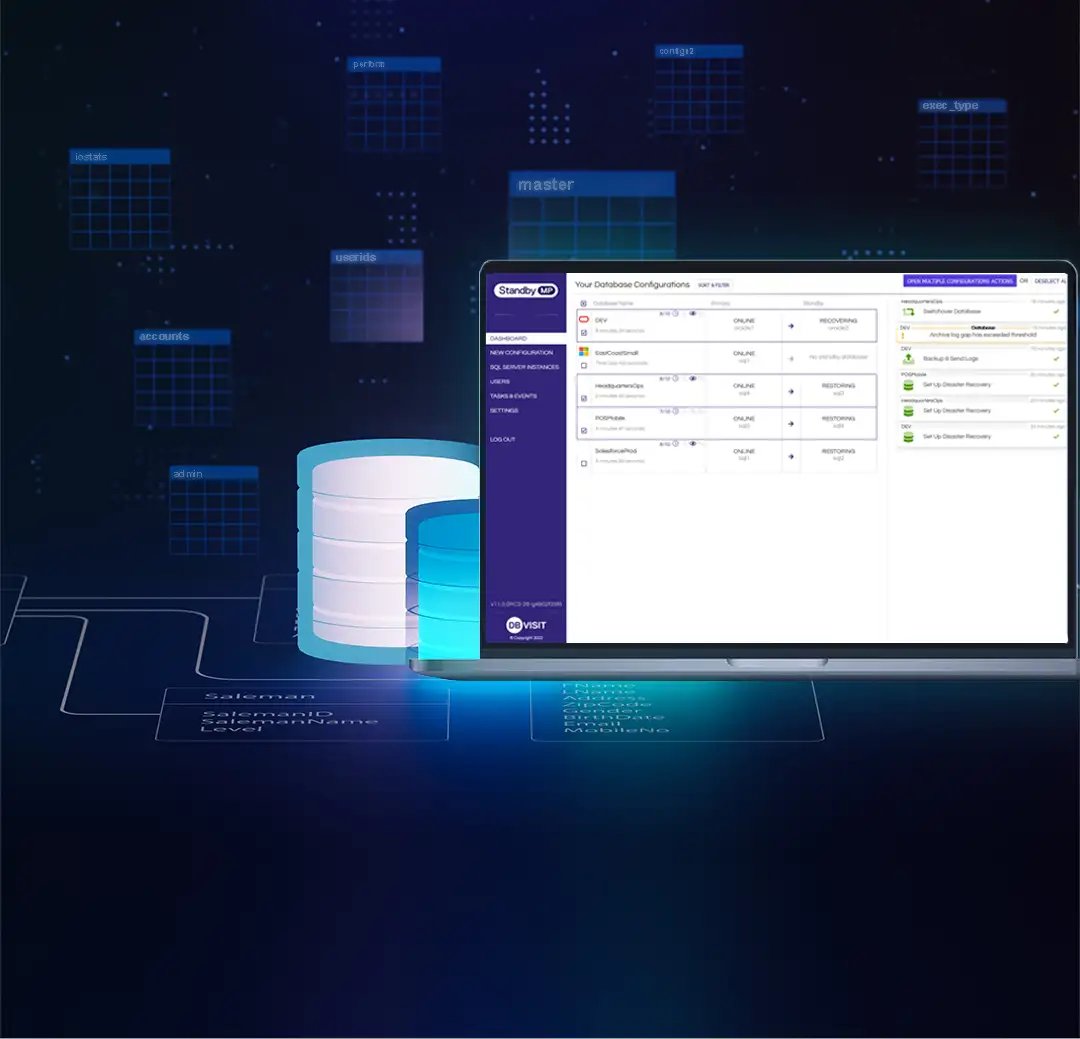
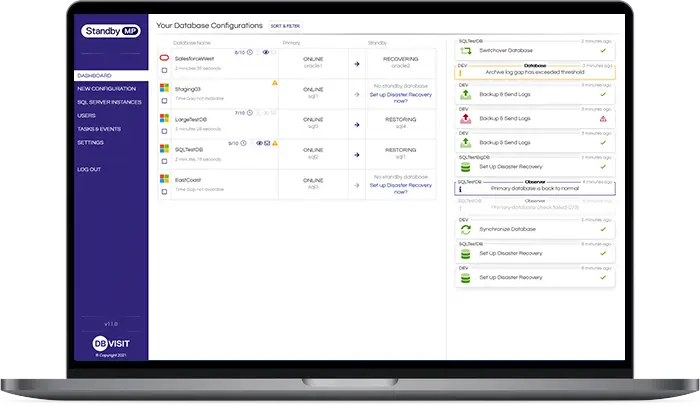
CONTINUOUS DATABASE PROTECTION
Your database is at the heart of your business.
Guarantee protection of your critical Oracle SE, SQL Server and PostgreSQL databases with a continuously updated standby database.
With Dbvisit's StandbyMP software, Gold Standard Disaster Recovery doesn't have to be difficult or expensive. ![]()





Why Dbvisit StandbyMP?








Find a local partner

